PRML勉強会
1.2.2 期待値と分散
期待値
-
-
-
- 離散・連続を問わず有限の点で近似可能
- の極限で厳密になる。
- サンプリング(11章)などで用いる
多変数の場合、平均を取る変数を指定する
この場合、 について周辺化されており、結果は についての関数になる。
条件付き期待値
-
- 条件付き確率に事前条件が反映されるだけ
-
連続変数についても同様
分散
-
- がその平均値 の周りでどれだけばらつくか、を表す
-
- 確率変数 についても分散を考えたもの
- 恒等関数をとるのと同義
分散の公式
期待値の期待値は期待値
共分散
と が同時に変動する度合い
独立であれば共分散は0
-
直感的には、
- 独立 『同時に変動する度合い』が0
-
を示せば良い
- → 次ページ
演習1.6
独立の定義 より
確率変数ベクトルの共分散
-
確率変数ベクトル , に関する共分散を表す行列
-
ベクトル の成分間の共分散は、
- 分散共分散行列(対角成分には分散、非対角成分には共分散)
1.2.3 ベイズ確率
ベイズ vs 頻度主義
- 頻度主義的・古典的確率
- 確率は、ランダムな繰り返し試行の頻度
- ベイズ的確率
- 確率は不確実性の度合い
- 事前分布という信念を導入する
- どこまで主観性を認めるかが違い
- PRMLでは、有用な場面ではどちらも用いる(ベイズ多め)
ベイズ確率を採用する根拠
- 確率の加法・乗法定理(ベイズの定理)が、信念の定量化・操作のための単純な公理集合から導かれる (Cox, 1946)
- 確率論 ブール論理を不確実性を含む場合に拡張したもの (Jaynes, 2003)
- その他にも多くの提案されている性質や公理が、確率の乗法・加法定理に従う
ベイズ確率
事後確率 尤度 事前確率
- データを観測する前にに関する仮説を事前分布として表現できる
- というデータを得た 事後 の、の不確実性を評価できる
ベイズ確率
- 尤度は確率分布ではない(積分は1になるとは限らない)
- は、事後確率を確率分布にするための定数
- 事後確率、 尤度、事前確率はすべての関数となっている
尤度関数
- ベイズ・頻度主義どちらでも重要となる
- ベイズでは
- データのみがあり、 は確率分布
- 頻度主義では
- は固定パラメータ、推定量として
- データの分布を考慮して得る(最尤推定)
事前分布
- 頻度主義では、コイン投げで3回連続で表が出ると、表が出る確率は100%になる
- ベイズ確率で、事前分布を導入すれば、それほど極端な値にはならない
- 逆に言えば、悪い事前分布を選べば高確率で悪い結果になる
- この場合、頻度主義では、交差確認(1.3節)を使える
- 逆に言えば、悪い事前分布を選べば高確率で悪い結果になる
ベイズの計算コスト
- モデル選択や予測に必要な 周辺尤度(エビデンス) の計算が重い
- 離散の場合は組み合わせ爆発
- 連続の場合には積分が解析不可能
- ガウス分布等であれば解析も可能
- MCMC(サンプリング法, 11章)や計算機の発達により実用的に
- 変分ベイズやEP法(期待値伝播法)等の決定論的近似法(10章)も寄与
1.2.4 ガウス分布
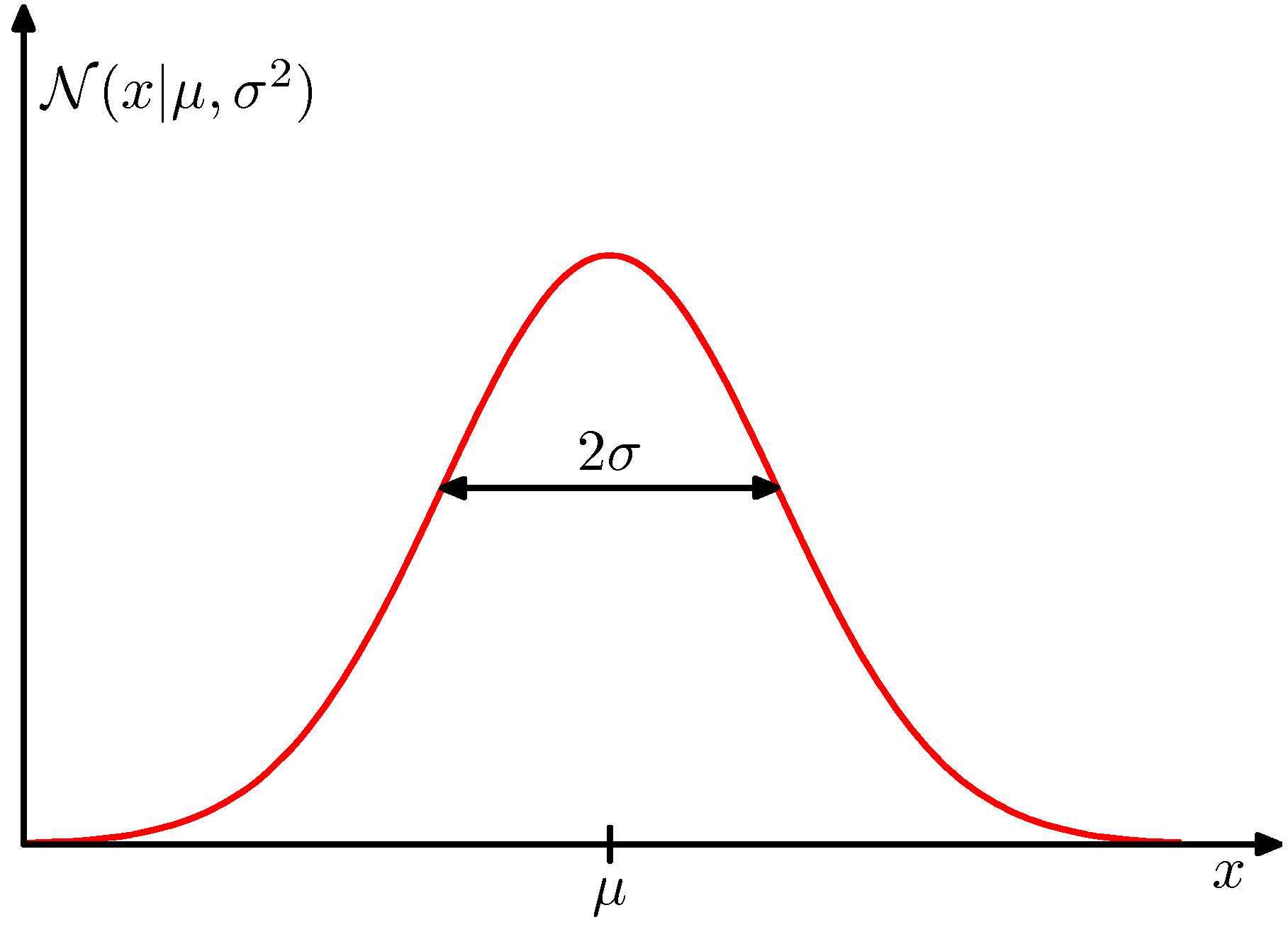
ガウス分布
- を精度パラメータという
- 確率密度である
ガウス分布
- 期待値・平均値
- 2次モーメント
- よって分散は
- 最頻値は平均値に一致
多変量正規分布
- 多変数にしたもの
- は共分散
- は共分散の行列式
- 詳細は2.3節
ガウス分布のパラメータ推定
- N個のデータ点が同じガウス分布から独立に生成されるとする
- データ点が同じ分布から独立に生成されることを、 独立同分布(i.i.d.) という
- independent identically distributed
- パラメータを求めたい
ガウス分布に対する尤度関数
- 独立な確率変数集合の同時分布なので、積をとればよい
- 与えられたデータの同時確率を最大化するパラメータを求めれば良い
ガウス分布に対する尤度関数の図示
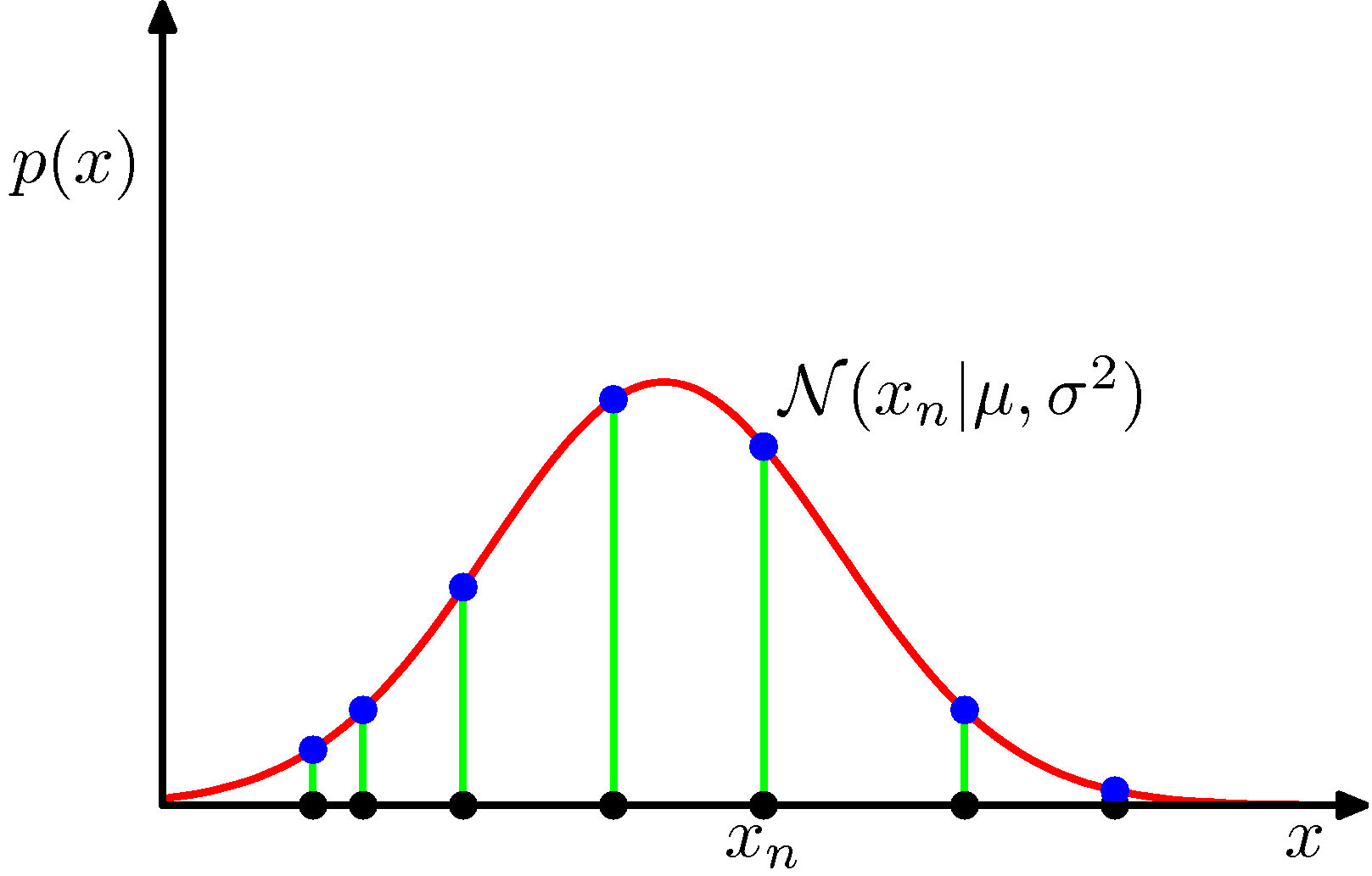
- イメージとしては、最大化することで、多くのデータが集まるところに最頻値を持ってこれる
尤度関数の最大化
- , に関して同時最大化
- 単調増加な対数をとる
- 解析が容易になる
- アンダーフロー防止(確率の積が和に変わる)
- 標本平均と標本分散を得る
尤度関数の最大化
- 最尤推定(Maximum Likelihood)の問題
- 分散が過小評価される(バイアス)
- サンプル数が増えればバイアスも減る
- 過学習に関連
分散の過小評価の直感的説明
- 各データ集合に2点のみ
- 平均の平均は真の平均に見えるが、
- 分散はどれも に過小評価されている
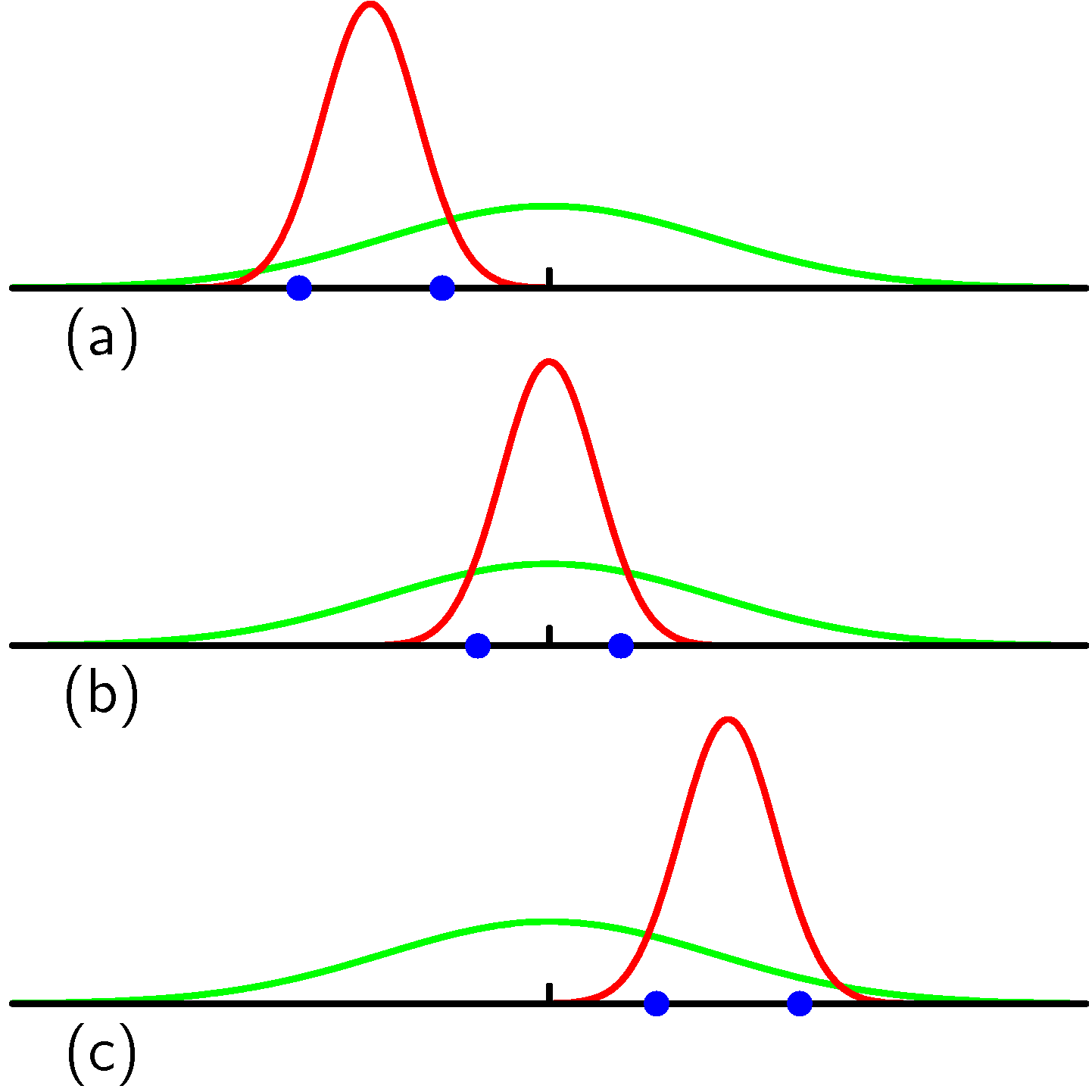
分散の過小評価の証明
分散パラメータの不偏推定量
より は分散パラメータの不偏推定量
10.1.3節で、この結果をベイズアプローチによって示す。
お詫び
GSuite, PowerPoint, PDFの推奨を見逃しており、慣れてて楽だったのでこれで書きましたが、数式のレンダリングが重すぎたり、PDFにするときにバグがあったので、次回移行GSuiteに移行します。
スライド版の数式を事前にレンダリングする処理が実装できたのと、PDF化はMarkdownの時点で済ませればOKなので、しばらくはこちらで運用します。