PRML勉強会
3.5.1 エビデンス関数の評価
復習
- 3.5では、対数エビデンスの最大化によって超パラメータ を決める
- 3.5最後の対数エビデンスの最大化についての議論は次節
- まずは、最大化する対数エビデンス の評価とモデル選択について
パラメータのおさらい
- は重みパラメータ の事前分布としたガウス分布の精度(分散の逆数)
- は観測値 にノイズとしたガウス分布の精度
周辺尤度
- を決定 → 重みパラメータ の分布が分かる
- 重みパラメータ と が決定 → 予測結果の分布が分かる
- これらの同時分布を重みパラメータ について周辺化したものが周辺尤度
周辺尤度の評価
ただし、
これを で平方完成すると
ただし、
で に対応し、
,
と定義した。 は事後分布の平均で以前出てきた同じ記号と一致する(3.50)。
上記より、目的の関数の指数部分の積分は以下のように解ける。
求めたかった周辺尤度の対数を整理すると
モデルエビデンス(対数表示)と多項式近似の次元数
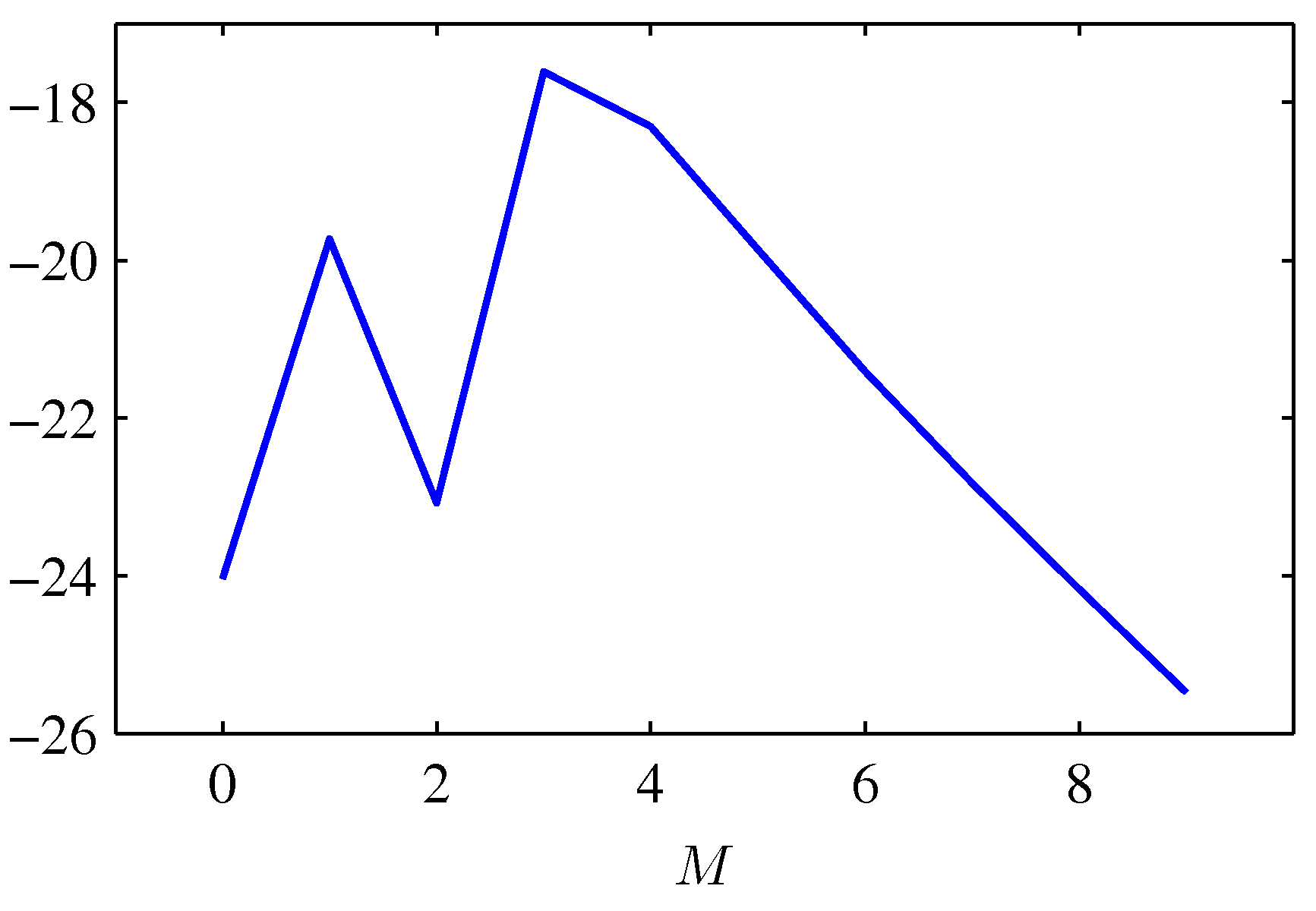
- 得られた結果とMの関係をプロット
- 実際に「観測されたデータを説明可能なモデルのうち最も単純なものが選ばれる」ことを可視化した具体例となっている
3.5.2 エビデンス関数の最大化
についての最大化
前節で得られた結果を超パラメータ について最大化していく。
まずは について。
の第2項について固有ベクトル方程式を考えると、
となる。
行列 全体で考えると、個々の固有値は となり、行列式は固有値の積(付録C.47)で計算できるので、
これを用いて先ほどの対数周辺尤度の に関する微分を0とすると
として整理すると
ここで、 は有効パラメータ数である(次節)。
繰り返し法
の右辺は に依存する(陰関数)
繰り返し法
- 一回の計算で答え求めることはできないので、以下の方法で数値計算を行う。
- 固有値 はこの依存関係に関しては定数となるので、あらかじめ求めておく。これと の値を使えば が求まる。
- を適当に初期化し、右辺を計算すると の再推定値が求まる。
- 2を収束するまで繰り返す。
- 最尤推定で必要となる独立なデータ集合は必要なく、訓練データのみから計算が可能。
についての最大化
と同じように、陰関数の形で を求めて、繰り返し法を行う。
行列 の固有値を としたので、 は に比例することに注意すると、
となり、
についての最大化
と同じように対数尤度の に関する微分を0として整理すれば
これは に関する陰関数となっている。
3.5.3 有効パラメータ数
と の解釈
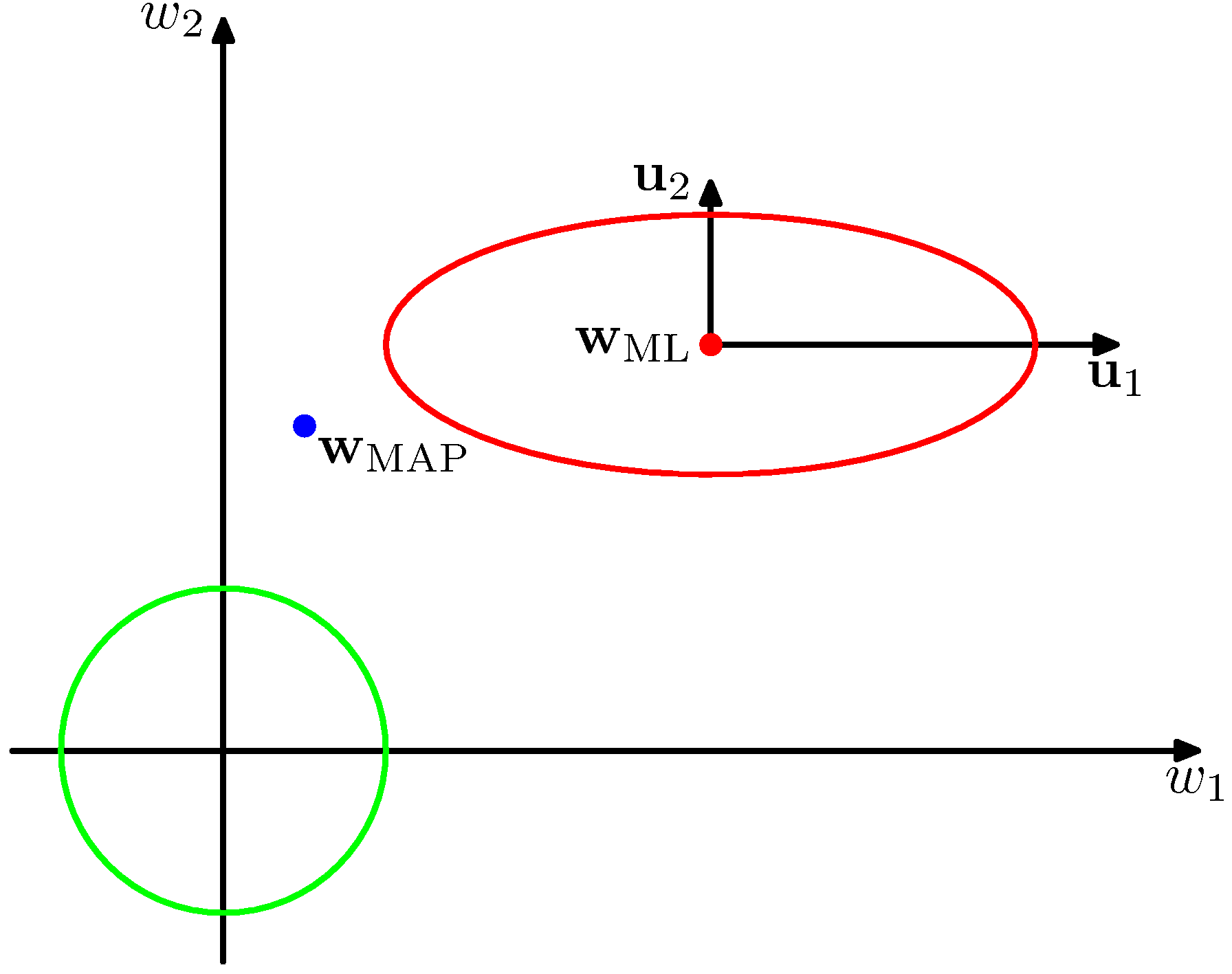
- 前節で求めた のベイズ推定解について考えてみる。
- 上図には、一様な事前確率と尤度関数の分布の等高線が、固有ベクトル が軸となるように回転して描かれている。
と の解釈
- を導入した際の固有ベクトル方程式を考えると、
- 固有値 は曲率で、図では となっている。
- 行列 は正定値行列なので、 は正。
- と定義したので、 となる。
と の解釈
-
となるとき、比 は1に近い値を取り、パラメータ は最尤推定値に近づく。このようなパラメータを well-determined parameter という。
-
逆に となるとき、比 は0に近い値を取り、パラメータ は自然と事前分布に近くなる。
と の解釈
- ベイズ推定では、 の推定値によって、有効なパラメータと事前分布と変わらないパラメータを決めていると分かる。
- このとき、 は先ほどの比の合計値となっており、有効なパラメータの数を表している。
の解釈
以下の分散の最尤推定解はノイズも含めた平均の推定で減った自由度を考慮していない。
10章でベイズ的に自然に導かれる以下の分散の不偏推定量は自由度の減少を考慮している。
前節で求めた についての陰関数は、最尤推定がバイアスに影響を受けるのに対して、有効なパラメータが 個推定されたことによる自由度の減少を考慮できている。
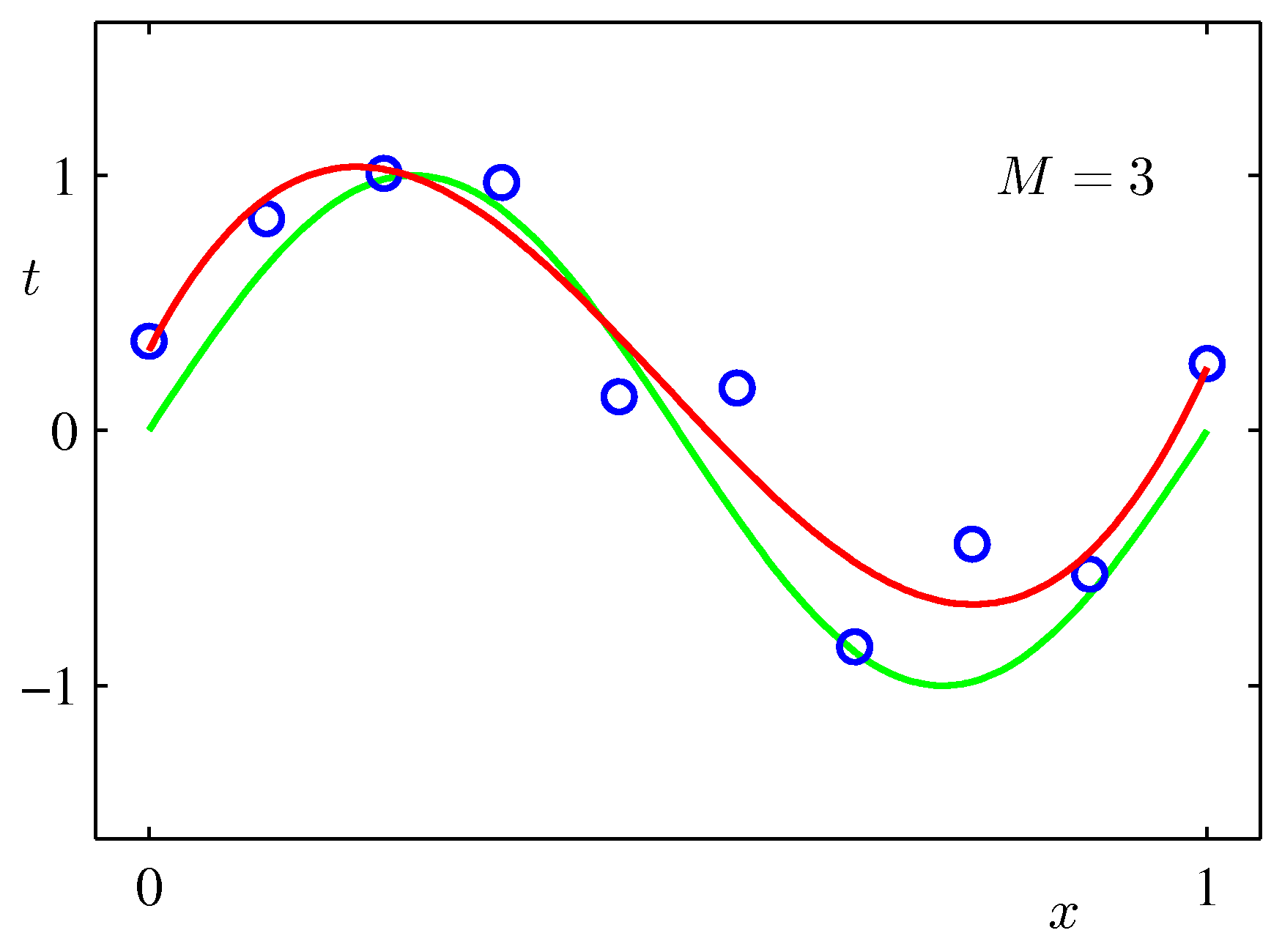
具体例
- 三角関数への多項式フィッティングについて、パラメータを10個にして再度考えてみる(バイアス項1つと基底関数9つ)。
- をデータを生成した真の値に固定して、 のベイズ推定解を求めてみる。
と の関係
- は重みパラメータ の事前分布としたガウス分布の精度(分散の逆数)
- で
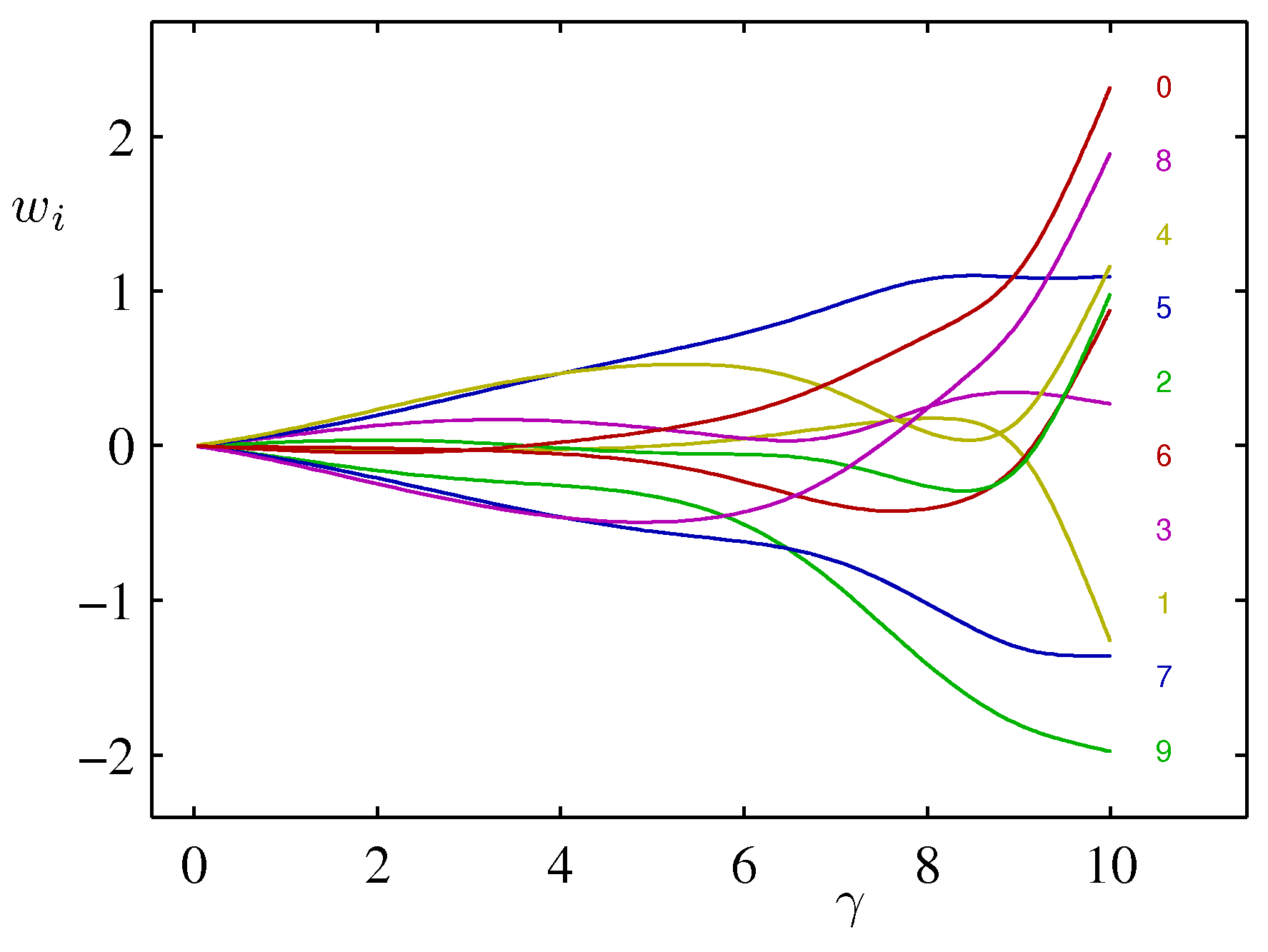
としたときの の推定解
データ点がモデルパラメータより十分大きい()とき、すべてのパラメータはwell-determined.
となり、
となるので両辺の交点が最適となる。
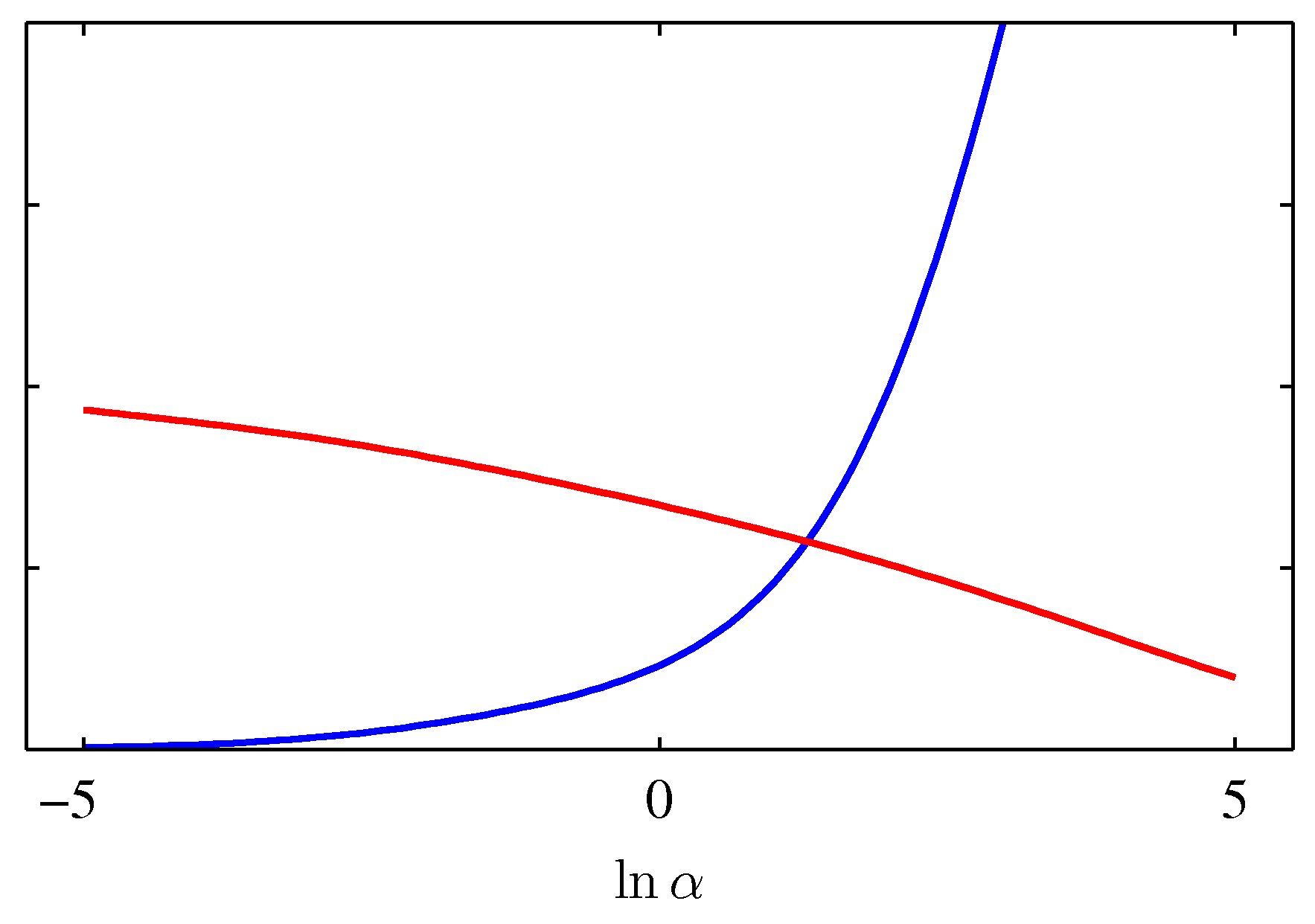
と
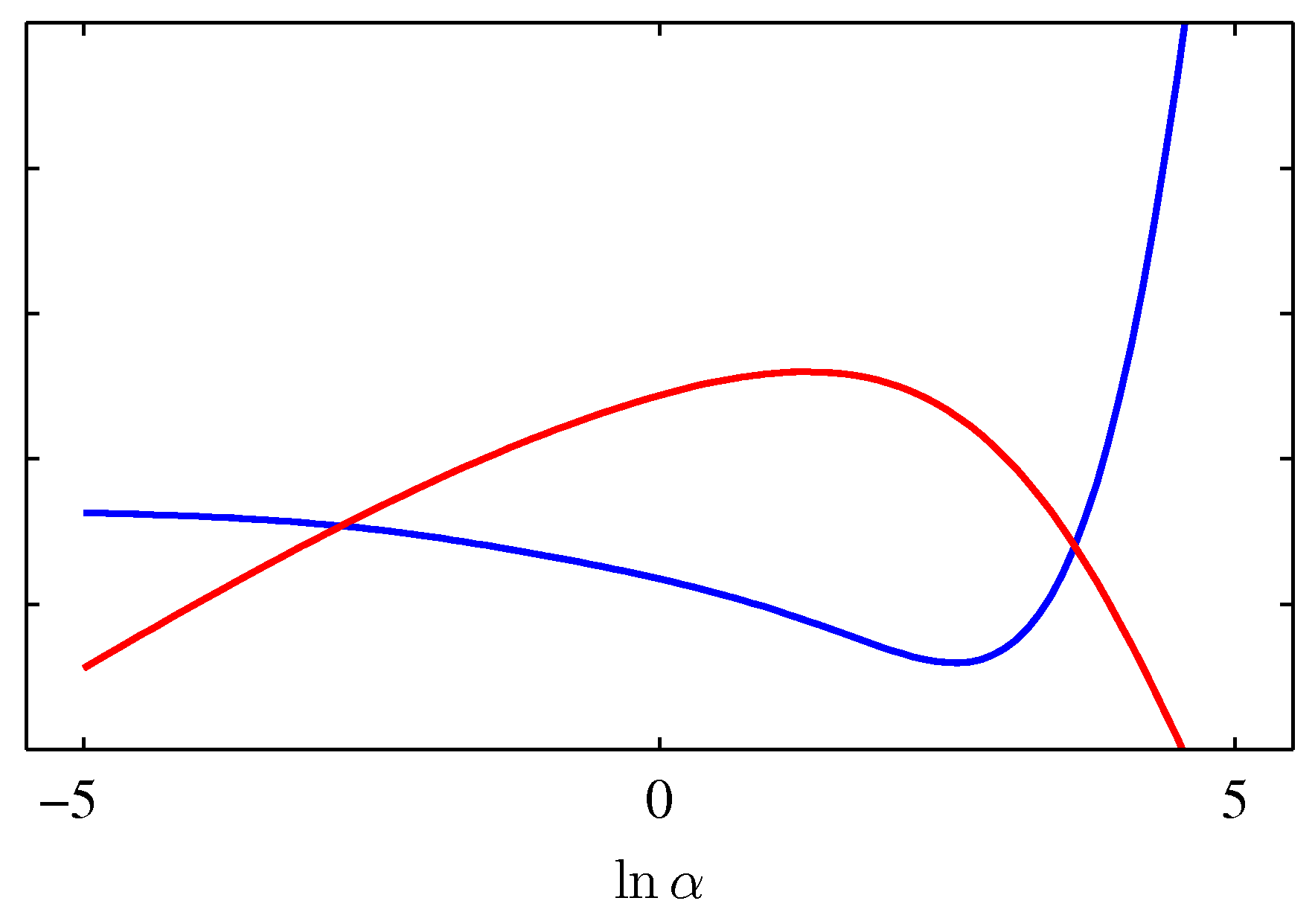
と テスト集合での誤差
3.6 固定された基底関数の限界
線形回帰モデル
- 固定された非線形基底関数 を線形結合したモデル
- パラメータの線形性を仮定
- 「微分とって0」で最尤解が求まった
- ベイズ推定もしやすかった
- 任意の非線形変換をモデル化できる
- が、パターン認識の問題を解く一般的な枠組みとはなり得ない
線形回帰モデルの問題点
- 訓練データ集合 の観測前に非線形基底関数 を固定している
- → 次元の呪い(1.4節)
- データの次元数に対して指数関数的に関数を用意する必要
現実的なデータ集合には、問題を軽減する2つの性質がある
- データの本質的な次元数は実際より低い(次元間の相関)
- 手書き文字で言えば、個々のデータの違いは垂直・水平・回転の3次元がメイン
- 基底関数を局所に絞ることができる
- RBF, SVM, RVM で使われる手法
- NNはシグモイド関数を適応的に配置できる
- 目標変数がデータ多様体の少数の可能な方向にのみ強く依存
- NNは入力空間で基底関数が反応する方向を選ぶことでこの性質を活用